What is Edge Computing?
| Edge Computing allows processing to be completed at the network edge, rather than at a centralised processing hub or data centre. |
Businesses are increasingly finding that, with a continuously growing number of networked devices, their networks are beginning to become overwhelmed with data. With many interconnected systems, such as IoT devices and sensors, high volumes of data are continuously generated and transmitted. Unfortunately, bandwidth limitations mean that networks are restricted in the amount of data they can transmit at any given time and therefore this leads to issues such as collisions which result in packet loss.
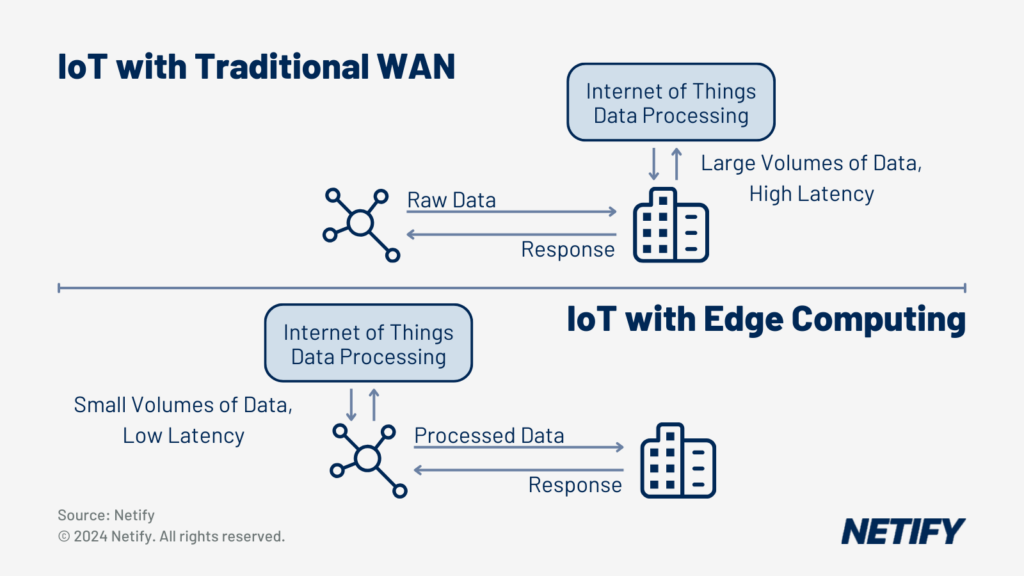
Avoiding these issues can be achieved by reducing the number of transmissions on the network, however these systems can be pivotal to business operations, meaning that disuse is out of the question. The alternative solution relies on reducing the volume of network traffic being transmitted, which is where Edge Computing comes in.
Edge Computing distributes computation and puts storage closer to the data source, such as the IoT sensor or localised edge device. By reducing the amount of data travelling long distances between clients and centralised servers, edge computing significantly lowers latency, reduces bandwidth utilisation and minimises transmission costs. Businesses also typically utilise Edge Computing due to processing data as close to the origin leads to quicker response times and greater efficiency in data handling. This localised processing means that decision making can be achieved in real time, whilst reducing the reliance on centralised cloud servers, which can be critical for latency-sensitive applications.
Edge vs. Cloud Vs. Fog Computing
To fully appreciate the benefits of Edge Computing, it's essential to distinguish it from related concepts like Cloud and Fog Computing, which each offer unique approaches to data processing and network architecture.
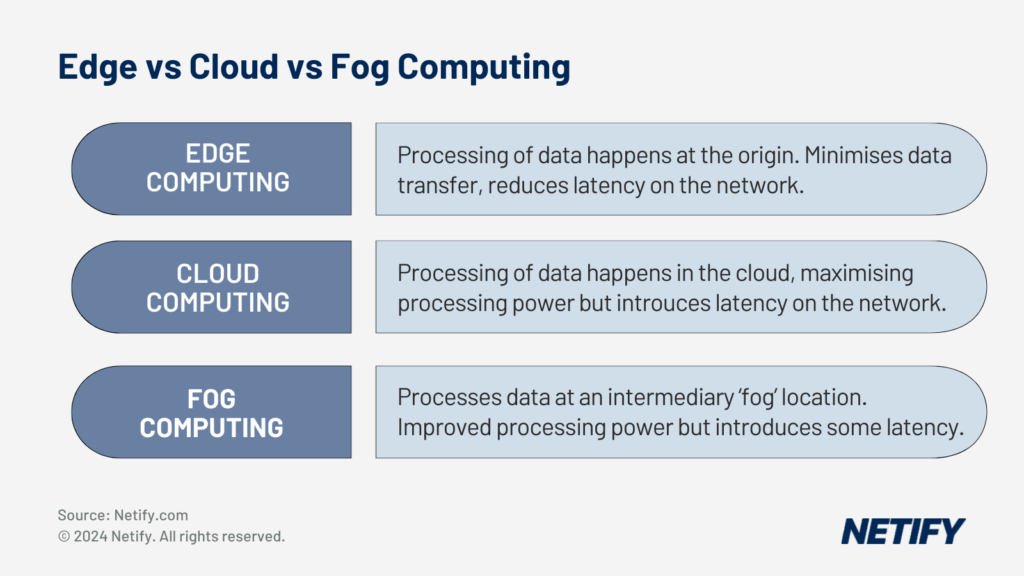
Edge Computing – processing of data at origin, edge devices or nearby servers in order to minimise travel of data from generation to processing.
Cloud Computing – processing of data at a centralised remote location. Comes with more computational power but introduces latency due to traversing long distances.
Fog Computing – processing of data at an intermediary of edge and cloud solutions. Provides some of the capabilities as cloud but isn’t as close to source as edge.
Key Components of Edge Computing
The key components within Edge computing include Edge devices, nodes or servers and data centres. Edge devices refer to data-generating systems such as Internet of Things (IoT) sensors, smartphones or industrial machines. Edge nodes and edge servers refer to computing resources near edge devices, with nodes processing and analysing the data generated by the devices. Finally, Edge data centres are small scale storage systems also capable of processing Edge device data.
Implementing Edge Computing
When implementing an Edge Computing architecture, businesses must ensure that they select the appropriate hardware to manage the processing demands at edge locations. It is also advisable that businesses identify the best location for edge sites and micro-datacentres, based on data sources and network configurations. By carefully choosing locations, businesses can ensure edge infrastructure can offer reliable operations even in diverse conditions, harsh climates or limited connectivity.
Advantages of Edge Computing
Moving the processing of data from central or cloud infrastructures, edge computing offers a wide range of advantages for businesses. The reduction in physical distance between data generation and processing means that travel time and latency is lowered, which can be crucial for real-time applications. By not transmitting high volumes of traffic over the network, the bandwidth utilisation is reduced, meaning that these resources can be allocated towards other network communications. The reduction in latency also enables real-time business intelligence, enabling businesses to utilise faster, more informed decision-making processes.
In some sectors, such as healthcare and finance, data sovereignty and regulatory compliance is also a concern, localised processing of data assists in meeting regulations and data security.
Advances Applications of Edge Computing
There are multiple advanced applications and use cases for Edge Computing. Within healthcare environments, Edge Computing supports with the real-time monitoring and analysis of patient medical devices, enabling immediate care. Meanwhile, manufacturers can also adopt Edge Computing architectures for real-time quality control, predictive maintenance purposes, improved efficiency and reduced downtime.
Challenges in Edge Computing Deployment
Edge devices are typically limited in their computational power, storage and energy resources when compared to cloud servers. This means that businesses must pre-plan their Edge deployment in order to ensure that capabilities match their business requirements in order to avoid delays or outages caused by a lack of resources.
Another challenge is that connectivity issues, such as unreliable networks due to service disruptions, impact data processing and synchronisation between nodes and cloud services. Businesses may wish to adopt failover mechanisms with cloud providers or instead implement a fog architecture for more business-critical operations to help avoid service disruptions.
Finally, due to their often limited computational power, Edge devices typically have less security functionality to protect against threats when compared to their cloud-based counterparts. Without integrations such as SD-WAN, network edges can also be left without much of the security provided in other parts of the network. This means that Edge devices are vulnerable to threats, with both devices and data at the edge potentially being breached or physically tampered with.
Trends in Edge Computing
Artificial Intelligence (AI) and Machine Learning (ML) are increasingly being adopted in edge devices and nodes to provide businesses with complex data analysis. This assists with decision-making processes as localised implementations reduce the depend on cloud-based AI.
The reduced reliance on large, energy intensive data centres is also viewed as being a more sustainable architecture. This makes Edge Computing architectures more favourable for businesses looking to improve their environmental impact.